ウェーブレット行列(wavelet matrix)
ウェーブレット行列(wavelet matrix)の話です
ウェーブレット行列
例えば,T = [5, 4, 5, 5, 2, 1, 5, 6, 1, 3, 5, 0] という配列があったとき,この配列の中で 7 番目に小さい値を求めたいとします.
最も単純なやり方は値をソートしてから T[7] にアクセスすることです(1-origin).
このような操作をいちいち行うことは,同様の操作を何回も繰り返し行いたいときには非効率です.
ウェーブレット行列では,あらかじめ索引を作っておくことで,配列に対する様々な操作を効率的に行うことができます.
ウェーブレット行列は内部で完備辞書(簡潔ビットベクトル)というデータ構造を利用します.
完備辞書についてはこちらを参照してください.
ウェーブレット行列で可能な操作
ウェーブレット行列は整数列Tに対して以下の操作を提供します1
| 操作 | 説明 | 計算量 |
|---|---|---|
| T[i]を復元する | ||
| T[1, i]中のcの出現回数を返す | ||
| T中のi番目のcの出現位置を返す | ||
| T[s, e]中のr番目に小さい値を返す | ||
| T[s, e]中で出現回数が多い順にその頻度とともにk個返す | ||
| T[s, e]の合計を返す | ||
| T[s, e]中に出現するx <= c < yを満たす値の合計出現数を返す | |
|
| T[s, e]中に出現するx <= c < yを満たす値を頻度とともに列挙する | ||
| T[s, e]中に出現する値を大きい順にその頻度とともにk個返す | ||
| T[s, e]中に出現する値を小さい順にその頻度とともにk個返す | ||
| T[s, e]中にでx <= c < yを満たす最大のcを返す | ||
| T[s, e]中でx <= c < yを満たす最小のcを返す | ||
| T[s1, e1]とT[s2, e2]の間で共通して出現する値と頻度を返す |
索引の構築
索引は各数値を最上位bitから順番に安定ソートしていくことで作成できます.
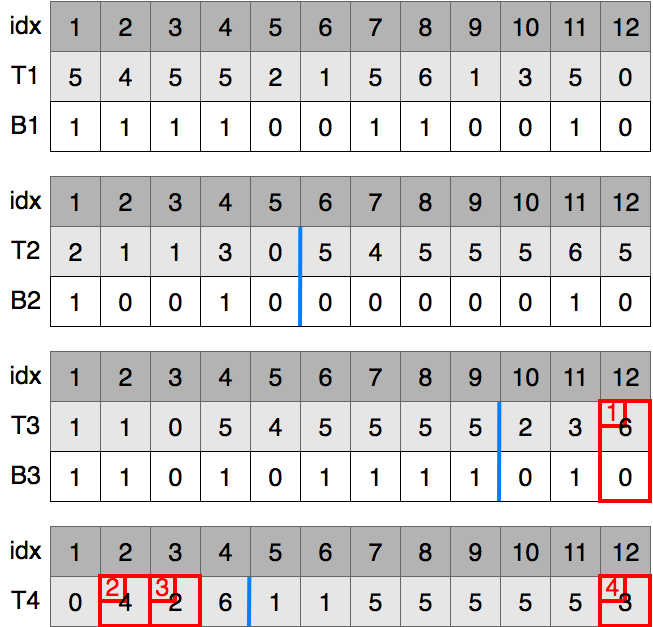
例としてT=[5, 4, 5, 5, 2, 1, 5, 6, 1, 3, 5, 0]の索引を作成します.
数列Tの1番目のbitを順番にとりだします2.5のbit表現は101なので1番目のbitである1、4のbit表現は100なので1番目のbitである1、...ととりだし索引として完備辞書に保存していきます3.とりだしたものがB1です.以降参考のためにTも書いていますが,保存するのはBのみです.

T1をB1に基づいて安定ソートします.つまり,2, 1, 1, 3, 0が左側に,5, 4, 5, 5, 5, 6, 5が右側に順序を保って移動します.移動したものがT2です.数列T2の2番目のbitを順番にとりだします.2のbit表現は010なので2番目のbitである1、1のbit表現は001なので2番目のbitである0、...ととりだして保存します.また、1番目のbitが0の数値は5個あるので,これを記録しておきます(図の青線).

T2をB2に基づいて安定ソートします.つまり,1, 1, 0, 5, 4, 5, 5, 5, 5が左側に、2, 3, 6が右側に順序を保って移動します.移動したあとは前回と同様に各数値の3番目のbitと,2番目のbitが0の数値の個数である9をそれぞれ保存します.

T3をB3に基づいて安定ソートします.0, 4, 2, 6が左側に,1, 1, 5, 5, 5, 5, 5, 3が右側に順序を保って移動します.4番目のbitはないので,今回はそれぞれの数値の開始インデックスを記録します4.0は1,1は5,2は3,3は12,4は2,5は7,6は4となります.また,3番目のbitが0の数値の個数である4も保存します.索引の作成はこれで終わりです.

最終的に以下の索引が得られました.説明のためにT4と書いてありますが,実際は各数値の開始インデックスを保存しています.このとき各数値が固まっていることがポイントになります.これはbitの逆順にソートされているためです.

操作
access
accessは数列Tの位置iの数値を求める関数です.
ウェーブレット行列はSelf-indexであり,元の数列Tを必要としません.逆にいえば数列Tをもっていないため,索引からどうにか値を復元する必要があります.
例として、T=[5, 4, 5, 5, 2, 1, 5, 6, 1, 3, 5, 0]のときのaccess(T, 7)を求めます.T[7]は5なのでaccess(T, 7) = 5となります.
accessの操作は,索引をたどりながらbitをひろっていくイメージです.
B1[7]をみます.B1はもとの数列Tと順序が同じなのでT[7]の1番目のbitが1ということがわかります.もちろんT1は保存していないのでこの時点で5ということはわかりません.
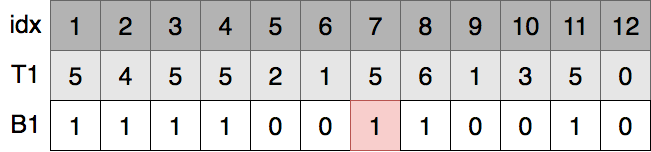
B1の位置7の数値がB2のどの位置に移るのかを求めます.この索引をどう作ったのかを思い出すと,B1の値が0のものをB2の左側に,値が1のものをB2の右側に順序を保って移動していたのでした.B1[7]は1なので,「B1に現れた0の個数 + Bの位置7までに出現した1の数」がB1の位置7の数値の移った場所とわかります.B1の0の個数は保存しており(図の青線),B1の位置7までに出現した1の数は
で求めることができます.B1の0の個数は5,
なので,5 + 5でB2の位置10に移ったとわかります.B2[10]=0なので,T[7]の2番目のbitは0だとわかりました.

同様にB2の位置10の数値がB3のどこに移ったのかを求めます.
なので,B3の位置8に移ったとわかります.B3[8]=1なので,T[7]の3番目のbitは1とわかりました.索引はB3までしかないので,T[7]は101,つまり5であること求めることができました.

まとめると以下のような探索の仕方になります

rank
rankは数列Tの位置iまでに数値cが何回出現したか求める関数です.
例として、T=[5, 4, 5, 5, 2, 1, 5, 6, 1, 3, 5, 0]のときのを求めます.Tの9番目までに5は4個あるので
となります.
rankの操作は,索引上でbitごとに右の位置を絞り込んでいくイメージです.
索引中で9番目は図の赤線の位置になります.この左側に5が何回出現しているか求めることが目標です.
索引の作り方を考えると,この赤線内の一番右の5(位置7)がT4のどこに移るのかを探すことができれば,位置9までに出現する5の個数がわかりそうです.これはT4で各数値が固まって出現しており,さらにその数値の出現順序が保たれているためです.もちろん現時点では位置7に5があるとはわからないのでbitごとに絞っていきます.

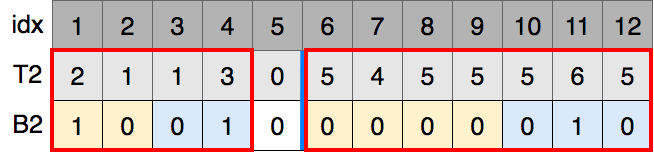
5の1番目のbitは1なので、B1の赤線内の数値の中で1番目のbitが1のものがB2のどこに移ったのかを探します.
= 6であり、1番目のbitが0の数値の数は5であることから11に移ることがわかります.

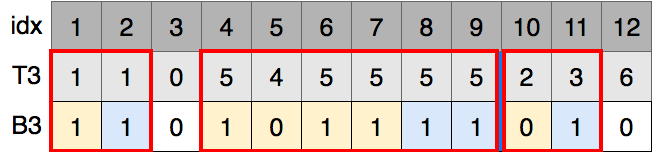
5の2番目のbitは0なので、B2の赤線内の数値の中で2番目のbitが0のものがB3のどこに移ったのかを探します.
となることから8に移ることがわかります.

5の3番目のbitは1なので,B3の赤線内の数値の中で3番目のbitが1のものがT4のどこに移るのかを探します.
であり,3番目のbitが0の数値の個数は4であることから10に移ることがわかります.索引構築時にT4での5の開始位置は7であると記録していたので
で4と求めることができました.

まとめると以下のような探索の仕方になります

select
selectは数列Tのi番目の数値cの位置を求める関数です.
例として、T=[5, 4, 5, 5, 2, 1, 5, 6, 1, 3, 5, 0]のときのを求めます.Tの4番目の5は位置7にあるので
となります.
selectはrankとは逆に索引を下からさかのぼっていくことで求められます.
T4で4番目に現れる5の位置を探します.5の開始位置は7なので7 + 4 - 1で10とわかります.T4の位置10の数値がB1のどの位置にあったのかがわかればselectを求めることができます.

T4の位置10の数値がB3のどこにあったのかを探します.5の3番目のbitは1なので
となるようなxを求めればいいです.これは
で求めることができ,位置8にあったとわかります.一応確かめてみると
となるので大丈夫そうです.

B3の位置8の数値がB2のどこにあったのかを探します.前回と同様に
となるxを求めます.
から位置10にあったとわかります.

B2の位置10の数値がB1のどこにあったのかを探します.
なので,
から位置7にあったとわかります.よって
と求めることができました.

まとめると以下のような探索の仕方になります.図の下から上に見ていってください.

quantile
quantileは数列Tのsからeの中でr番目に小さい値を返す関数です.
例としてT=[5, 4, 5, 5, 2, 1, 5, 6, 1, 3, 5, 0]のときのを求めます.Tの2から11をソートすると1, 1, 2, 3, 4, 5, 5, 5, 5, 6なので,
となります.
索引中で2番目から11番目は図の赤線の内側になります.この中で8番目に小さい数を求めることが目標です.
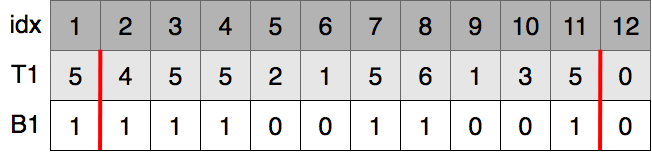
B1の赤線内の0の個数と1の個数を数えます.
,
なので0は
で4個です.赤線の数値は10個なので,1の個数は
で6とわかります.
次に,8番目に小さい数の1番目のbitが0と1のどちらなのかを考えます.B1の0と1は各数値の1番目のbitなので,各数値を小さい順に並べると0, 0, 0, 0, 1, 1, 1, 1, 1, 1となるはずです.このことから8番目に小さい数の1番目のbitは1であるとわかります.
8番目に小さい数がB1の赤線内の1のどれかとわかったので,これらがB2だとどの範囲なのかを探します.これは赤線内で一番左側の1(ここでは位置2)と一番右の1(ここでは位置11)がどこに移ったかを求めればいいです.
赤線内で1番左の1がどこにあるか求めるために,左の赤線である位置2までに1が何個あったのか計算します.なので1個あるとわかります5.このことから,赤線内の一番左の1はB1の2個目とわかり,移動先は
となります.
赤線内で1番右の1がどこにあるか求めるために,右の赤線である位置11までに1が何個あったのか計算します.なので7個あるとわかります.このことから,赤線内の一番右の1はB1の7個目とわかり,移動先は
となります.
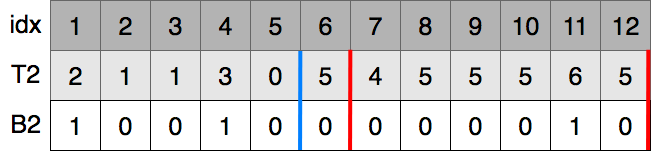
B2の赤線内の0の個数と1の個数を数えます.手順1と同じ方法で0の数が5,1の数が1とわかります.B2の赤線内の数値を順番に並べると0, 0, 0, 0, 0, 1となります.手順1では8番目の位置を探していましたが,その際に0を4つ飛ばしたので今回は8 - 4で4番目を探すことになります.0, 0, 0, 0, 0, 1の4番目に小さい数は0なので,4番目に小さい数の2番目のbitは0であるとわかります6.B2の赤線内の0がB3のどこに移ったか探すと位置5から位置9とわかります.
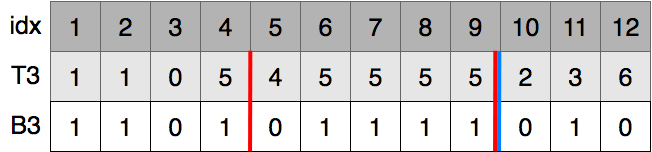
同様の手順を繰り返します.B3の赤線内の数値を順番に並べると0, 1, 1, 1, 1となります.手順2では数値を飛ばしていないので,この中で4番小さい数値を探します.これは1なので,8番目に小さい数の3番目のbitは1であるとわかります.B3の赤線内の1がT4のどこに移ったか探すと位置8から位置11とわかります.

T4のなかでの赤線内で4番目に小さい数値を探すと位置11の5です.5の開始位置は7なので,
はTの5番目に現れる5と求めることができました.
まとめると以下のような探索の仕方になります

topk
topkは数列Tのsからeの中で出現回数が多い順にk個の値を返す関数です.
例としてT=[5, 4, 5, 5, 2, 1, 5, 6, 1, 3, 5, 0]のときのを求めます.各数値の出現回数は1が2回,2が1回,3が1回,4が1回,5が3回,6が1回なので,
は[(5, 3), (1, 2)]となります.
topkは範囲の大きさをkeyとした優先度付きキューを使うことで計算できます.
B1[2, 10]をqueにいれます.赤枠がqueの要素,左上の赤の数値がque内の順序を表します.
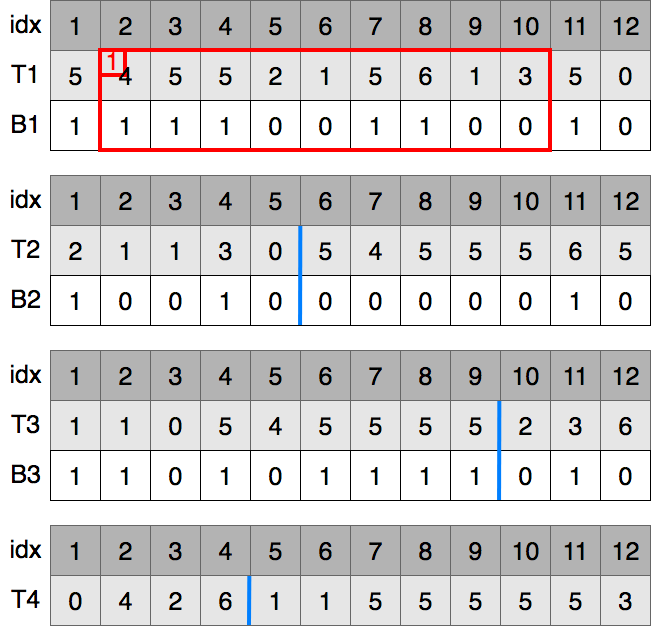
queの先頭要素をとりだします.この要素をbitが0の要素と1の要素に分解したものをqueにいれます.
B1の赤枠内のbitが0の要素の値は2, 1, 1, 3であり,これらの行先はB2の1から4です.
B1の赤枠内のbitが1の要素の値は4, 5, 5, 5, 6, 5であり,これらの行先はB2の7から12です.

queの先頭要素であるB2[7, 12]をとりだし,0の要素と1の要素に分解したものをqueにいれます.
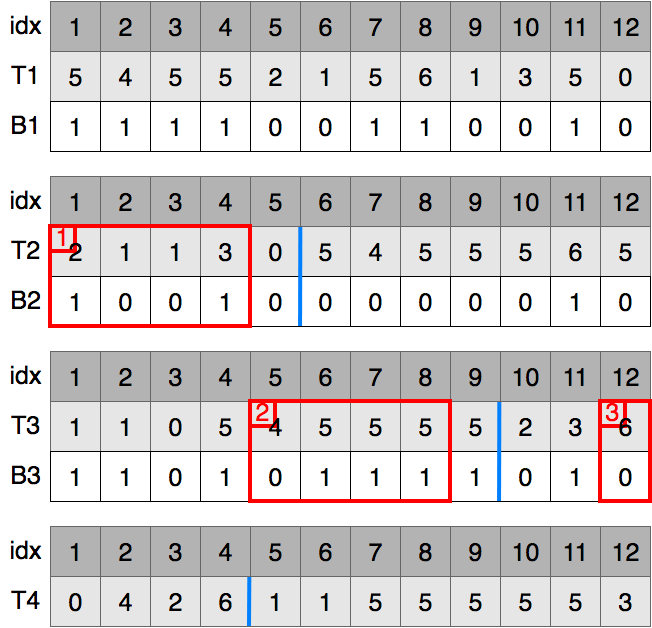
同じ操作を繰り返します
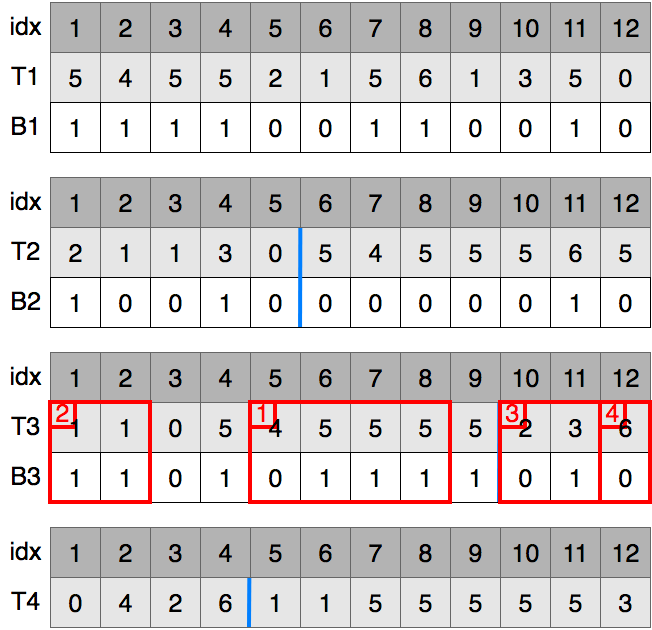
同じ操作を繰り返します
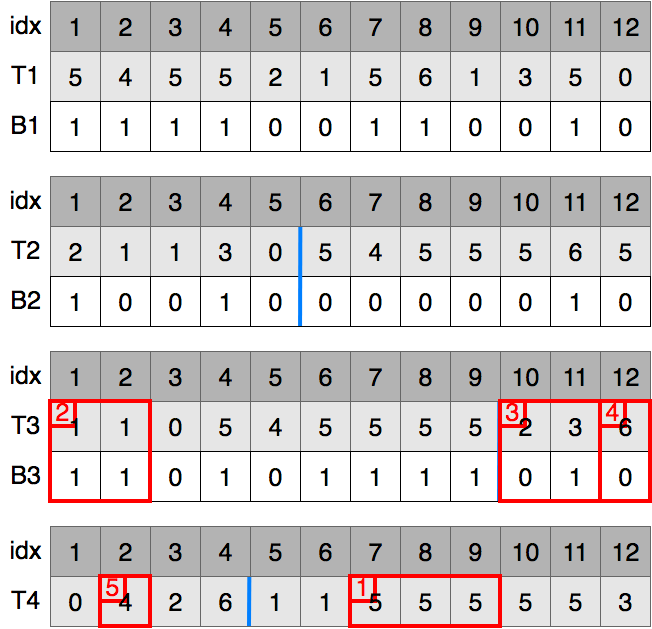
queの先頭要素であるT4[7, 9]をとりだします.これ以上分解できないので値5が3つ出現するとわかりました.

同じ操作を繰り返します

同じ操作を繰り返します

9.queの先頭要素であるT4[5, 6]をとりだします.これ以上分解できないので値1が2つ出現するとわかりました.kは2なのでこれで終了します.
sum
sumは数列Tのsからeの中の合計を返す関数です.
topkを求め,値と頻度の積を足し合わすことで求められます.
intersect
intersectはT[s1, e1]とT[s2, e2]の間で共通して出現する値と頻度を返す関数です.
例としてT=[5, 4, 5, 5, 2, 1, 5, 6, 1, 3, 5, 0]のときのを求めます.T[1, 6]は[5, 4, 5, 5, 2, 1],T[7, 11]は[5, 6, 1, 3, 5]なので共通して出現する値は1と5です.T[1, 6]には1が1つ,5が3つ,T[7, 11]には1が1つ,5が2つあるため,例
となります.
intersectは(s1, e1, s2, e2)を要素にもつqueを使うことで計算できます.
(1, 6, 7, 11)ををqueにいれます.queにいれた状態が下の図です.赤枠がqueの要素を表し,黄がT[s1, e1]に含まれる値,青がT[s2, e2]に含まれる値です.

queの先頭要素(1, 6, 7, 11)をとりだし,0の行先と1の行先に分割します.
0に行く黃の要素は2, 1,青の要素は1, 3なので(1, 2, 3, 4)を作成しqueに追加します.
1に行く黃の要素は5, 4, 5, 5, 5,青の要素は5, 6, 5なので(6, 9, 10, 12)を作成しqueに追加します.
queの先頭要素である(1, 2, 3, 4)をとりだし,0の行先と1の行先に分割しqueに追加します.
同様に(6, 9, 10, 12)も処理します.このとき0に行くのは5, 4, 5, 5, 5, 5であるため(4, 7, 8, 9)を作成しqueにいれます.1に行くのは青の6だけであり黄色の要素が存在しないため処理は行いません.このように青か黃どちらかだけからなる要素ができた場合は共通する値はないということなのでそれ以上処理する必要がなくなります.
queの先頭要素である(1, 1, 2, 2)をとりだし,処理します.(4, 7, 8, 9)も同様に処理しますが,0に行くのは黃の4だけなのでqueに追加しません.(10, 10, 11, 11)も0に行くのは黃の2だけ,1に行くのは青の1だけなのでqueに追加しません.

queの先頭要素である(5, 5, 6, 6)をとりだします.行先はもうないため黃の1が1つ,青の1が1つと求められます.同様に(7, 9, 10, 11)から黃の5が3つ,青の5が2つと求められました.
まとめると以下のような探索の仕方になります

ソース
いろいろな人の実装
- GitHub - hillbig/wat-array: Automatically exported from code.google.com/p/wat-array
- GitHub - hiroshi-manabe/wavelet-matrix-cpp: A test implementation of Wavelet Matrix based on wat-array by Daisuke Okanohara.
- GitHub - arosh/fmx: full text search engine based on compact data structures
- Wavelet Matrix (ウェーブレット行列) を実装してみた - antaの競技プログラミング練習日記
- ウェーブレット行列を実装した - hirokazu1020の日記
- http://algoogle.hadrori.jp/algorithm/wavelet.html
参考
- The wavelet matrix: An efficient wavelet tree for large alphabets
- Wavelet Trees for All
- New Algorithms on Wavelet Trees and Applications to Information Retrieval
- Compact Data Structures: A Practical Approach
- 高速文字列解析の世界――データ圧縮・全文検索・テキストマイニング (確率と情報の科学)
- ウェーブレット木の効率的で簡単な実装 "The Wavelet Matrix" - EchizenBlog-Zwei
- 中学生にもわかるウェーブレット行列 - アスペ日記
- ウェーブレット行列による RankLessThan() - アスペ日記
- ウェーブレット行列による QuantileRange() - アスペ日記
- Wavelet Matrix | PDF
- 論文紹介:The wavelet matrix